Ghost 调教日志 - 解决中文摘要的截取问题

在新版的 Ghost 中首页中文文章的摘要总是会出现截取字数太多,和下面的图片一样。但是如果直接减少模板的 excerpt 的 words,对于英文文章又会出现字数过少。如果更改 words 到 characters,又会出现英文单词截词只会截一半,展现效果不够美观好看。研究一段时间之后,终于算是找到了比较好的解决方式。

Ghost 的文章摘要采用的一个叫做 Downsize 的库,这个库本身支持 words,characters,round,append 这些参数。但是从 Ghost 的源码上来看的话,Ghost 只支持了 words,characters 参数来进行截取摘要,而我们这次主要就是需要使用 append 参数,所以我们需要对 Ghost 进行一些改(调)造(教)。
以下是 Ghost 截取摘要的源码(ghost/current/core/server/helpers/excerpt.js):
// # Excerpt Helper
// Usage: `{{excerpt}}`, `{{excerpt words="50"}}`, `{{excerpt characters="256"}}`
//
// Attempts to remove all HTML from the string, and then shortens the result according to the provided option.
//
// Defaults to words="50"
var proxy = require('./proxy'),
_ = require('lodash'),
SafeString = proxy.SafeString,
getMetaDataExcerpt = proxy.metaData.getMetaDataExcerpt;
module.exports = function excerpt(options) {
var truncateOptions = (options || {}).hash || {};
truncateOptions = _.pick(truncateOptions, ['words', 'characters']);
_.keys(truncateOptions).map(function (key) {
truncateOptions[key] = parseInt(truncateOptions[key], 10);
});
return new SafeString(
getMetaDataExcerpt(String(this.html), truncateOptions)
);
};
改造步骤
在 hbs 模板中支持 round 与 append 参数
首先是需要支持 round,append 参数才行,所以先更改中间的一段,使其能够读取这两个参数。
改造前:
truncateOptions = _.pick(truncateOptions, ['words', 'characters']);
_.keys(truncateOptions).map(function (key) {
truncateOptions[key] = parseInt(truncateOptions[key], 10);
});
改造后:
truncateOptions = _.pick(truncateOptions, ['words', 'characters', 'append', 'round']);
_.keys(truncateOptions).map(function (key) {
switch (key) {
case "words":
case "characters":
truncateOptions[key] = parseInt(truncateOptions[key], 10);
break;
case "round":
truncateOptions[key] = String(truncateOptions[key]).toLowerCase() === "true";
break;
}
});
修改 hbs 模板
这样的话我们就能读取所有 Downsize 所支持的参数了。可以在 hbs 模板中使用这些参数了,修改模板文件 post-card.hbs(ghost/content/themes/casper/partials/post-card.hbs)。
改造前:
改造后:
更改 getMetaDataExcerpt
由于 excerpt.js 最后调用的 getMetaDataExcerpt 方法会把文章的所有 html 标签去掉,所以会导致段落无法识别,round 参数也无法使用。所以我们在这里需要更改 excerpt.js 的处理逻辑。
改造前:
var proxy = require('./proxy'),
_ = require('lodash'),
SafeString = proxy.SafeString,
getMetaDataExcerpt = proxy.metaData.getMetaDataExcerpt;
module.exports = function excerpt(options) {
var truncateOptions = (options || {}).hash || {};
truncateOptions = _.pick(truncateOptions, ['words', 'characters']);
_.keys(truncateOptions).map(function (key) {
truncateOptions[key] = parseInt(truncateOptions[key], 10);
});
return new SafeString(
getMetaDataExcerpt(String(this.html), truncateOptions)
);
};
改造后:
var downsize = require('downsize');
var proxy = require('./proxy'),
_ = require('lodash'),
SafeString = proxy.SafeString,
getMetaDataExcerpt = proxy.metaData.getMetaDataExcerpt;
module.exports = function excerpt(options) {
var truncateOptions = (options || {}).hash || {};
truncateOptions = _.pick(truncateOptions, ['words', 'characters', 'append', 'round']);
_.keys(truncateOptions).map(function (key) {
switch (key) {
case "words":
case "characters":
truncateOptions[key] = parseInt(truncateOptions[key], 10);
break;
case "round":
truncateOptions[key] = String(truncateOptions[key]).toLowerCase() === "true";
break;
}
});
var result = downsize(String(this.html), truncateOptions);
// Strip inline and bottom footnotes
result = result.replace(/<a href="#fn.*?rel="footnote">.*?<\/a>/gi, '');
result = result.replace(/<div class="footnotes"><ol>.*?<\/ol><\/div>/, '');
// Strip other html
result = result.replace(/<\/?[^>]+>/gi, '');
result = result.replace(/(\r\n|\n|\r)+/gm, ' ');
return new SafeString(result);
};
我们可以看到,在这里我们跳过了 getMetaDataExcerpt 方法直接使用 downsize 处理 html,获取段落,然后通过一系列的正则表达式去掉所有的
html 标签,就可以得到我们最后的效果了。
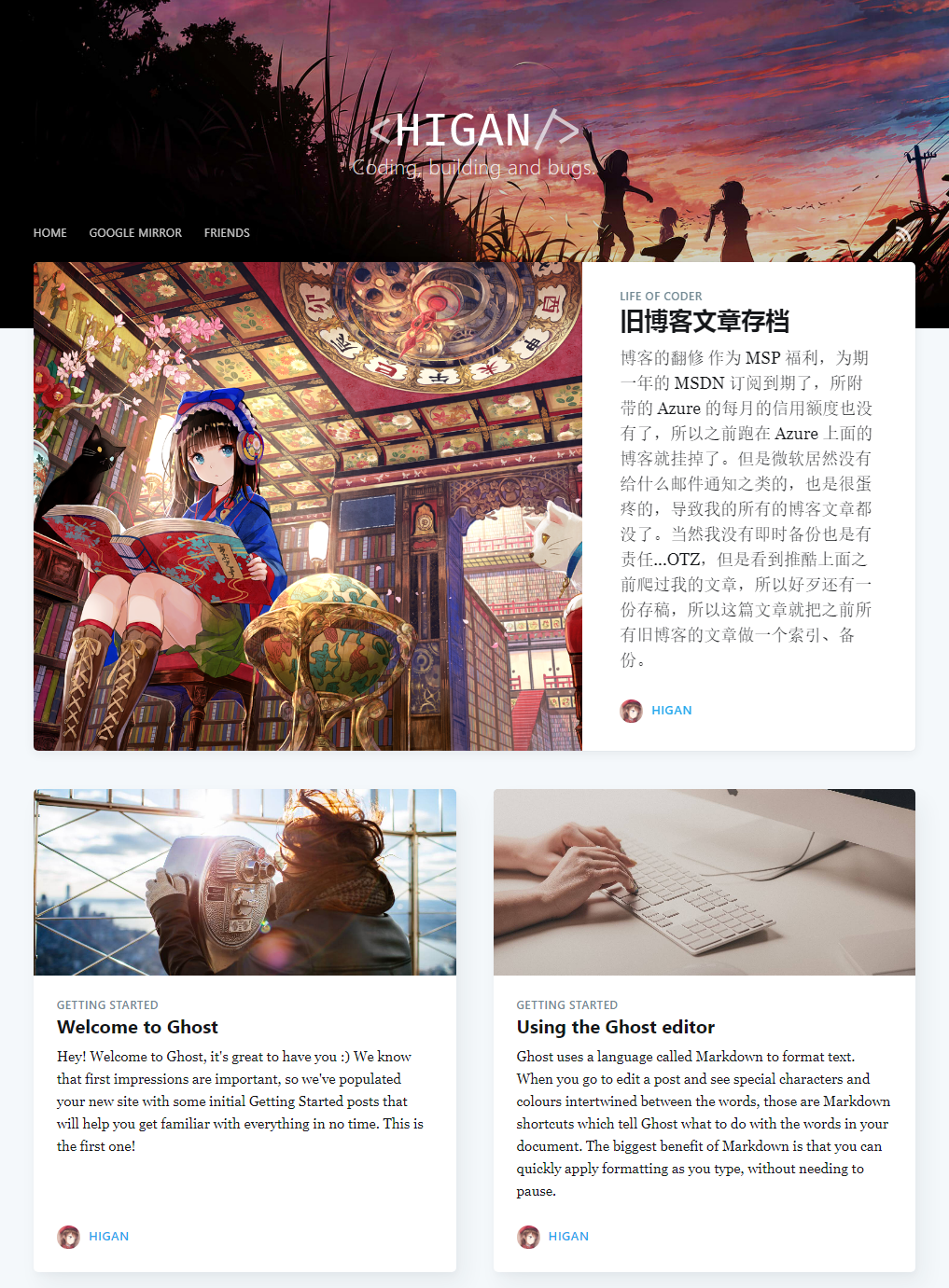 可以看到,对比之前的摘要,新的摘要截取得更加科学,美观,基本就是第一段的内容。所以与这个效果配合起来,文章的第一段写一些总结效果最好。
可以看到,对比之前的摘要,新的摘要截取得更加科学,美观,基本就是第一段的内容。所以与这个效果配合起来,文章的第一段写一些总结效果最好。